Data Deduplication (дедупликация данных) - это возможность уменьшать пространства за счет удаления одной части дублирующих данных. Впервые Microsoft выпустила такую возможность в Windows Server 2012 и технически она менялась вплоть до самой последней версии сервера 2019. Технология дедупликации реализована у множества брендов в том числе: HP, CISCO, IBM и VmWare.
Для чего нужна и как работает дедупликация
Если взять обычный файловый или бэкап сервер, то мы увидим большой объем полностью или частично дублирующих файлов. На файловых серверах это полные копии данных, которые хранят разные пользователи, а на бэкап серверах - это минимум файлы с ОС. С определенным интервалом происходит процесс сканирования блоков с данными в 32-128 Кб и проверка уникальности. Такие блоки так же называются чанками (chunk/куски) и это важно запомнить, так как это название вы будете видеть в Powershell. При нахождении одинаковых чанков они оба будут удалены и заменен ссылкой на уникальный чанк помещенный в специальное место. Такие ссылки будут помещены в папку System Volume Information, а блоки, с уникальными данными, в контейнеры. Все такие данные, в Windows Server, имеют возможность восстановления в случае критических повреждений.
Дедупликация работает по томам и в целом мы можем увидеть такую схему:
- Оптимизированные файлы, состоящие из ссылок на уникальные чанки;
- Чанки, организованные в контейнеры, которые сжимаются и помещаются в хранилище;
- Не оптимизированные файлы.
Бренды реализуют дедуликацию по-разному. Она может работать с целым файлом, блоком или битом. В Windows Server реализована только блочная дедупликация. Файловая дедупликация была реализована в Microsoft DPM, но в этом случае, файл измененный на бит, уже будет являться новым и это было бы оправдано в случаях бэкапа. В сетях можно увидеть битовую.
Картинки, которые так же немного демонстрирует описанный процесс:


Кроме реализации дедупликации на уровне томов, у некоторых брендов, она работает и на уровне сети. Вместо отправки файлов будут отправлены хэш суммы (SHA-1, SHA-2, SHA-256) чанков и если хэш будет совпадать с тем, что уже имеется на стороне принимающего сервера, он не будет перенесен. Похожая возможность, в Windos Server, реализована с помощью работы BranchCache и роли Data Deduplication.
Изменения в версиях
Дедупликация не работает на томах меньше чем 2 Гб.
Windows Server 2012 + r2
- файловая система только NTFS;
- поддержка томов до 10 Тб;
- не рекомендуется использовать с файлами объем которых достигает 1 Тб;
- 2012 не поддерживает VSS (не может работать с открытыми файлами) с 2012 r2 эта поддержка появилась;
- один режим работы.
Windows Server 2016
- файловая система только NTFS;
- поддержка томов до 64 Тб;
- дедупликация работает с первым 1 Тб данных у файла (ранее могли быть ошибки после 1 Тб данных, но исправилась после выпуска обновлений kb3216755, kb4025334, kb4013429);
- три режима работы;
- возможность доступна в Nano Server.
Windows Server 2019
- файловая система NTFS или ReFS;
- поддержка томов до 64 Тб;
- работа с первыми 4 Тб данных у файла (ранее могли быть ошибки после 1 Тб данных, но исправилась после выпуска обновлений kb3216755, kb4025334, kb4013429);
- три режима работы;
- интеграция с BranchCache;
- возможность доступна в Nano Server.
Процесс дедупликации происходит по расписанию, а не "на лету", и из-за этого есть общие рекомендации по размеру разделов. Если разделы будут больше описанных выше, то скорость работы сканирования может быть меньше чем обновление этих файлов. В версии 2016 в процесс дедупликации была добавлена парализация, что позволило увеличить скорость и общий объем работы для работы этой роли:

Если вы используете кластер, то роль должна быть установлена на каждую ноду.
Где и когда применять
Связи с причинами описанными выше есть рекомендации, где имеет смысл использовать роль:
- Файловые сервера
- VDI
- Архивы с бэкапом
Фактически вы не сможете использовать эту роль со следующими условиями (без учета разницы в версиях):
- файлы зашифрованные (EFS);
- файлы с расширенными атрибутами;
- размер файлов меньше чем 32 Кб;
- том является системным или загрузочным;
- тома не являющиеся дисками (сетевые папки, USB носители).
В теории вы можете работать с любыми остальными типами файлов и серверов, но дедупликация очень ресурсозатратный процесс и лучше следовать объемам, указанным выше. Допустим у вас на сервере много файлов формата mp4 и вы предполагаете, что существенная их часть разная - вы можете попробовать исключить их из анализа. Если сервер будет успевать обрабатывать остальные типы файлов, то вы включите файлы mp4 в анализ позже.
Так же не стоит использовать дедупликацию на базах данных и любых других данных с высоким I/O, так как они содержат мало дублирующих данных и часто меняются. Из-за этого процесс поиска уникальных данных, а следовательно и нагрузка на сервер, может проходить в пустую.
Дедупликация работает по расписанию и может использовать минимум и максимум мощностей. В зависимости от общего объема и мощности сервера разный процесс дедупликации (их 4) может занять как час, так и дни. Microsoft рекомендует использовать 10 Gb оперативной памяти на 10 Тb тома. Часть операций нужно делать после работы, какие-то в выходные - все индивидуально.
На некоторых программах бэкапа, например Veeam, тоже присутствует дедупликация архивов. Если вы храните такой бэкап на томе Windows, с такой же функцией, вам нужно выполнить дополнительные настройки. Игнорирование этого может привести к критическим ошибкам.
При копировании файлов между двумя серверами, с установленной ролью, они будут перенесены в дедуплицированном виде. При переносе на том, где этой роли нет - они будут сохранены в исходном состоянии.
Microsoft не рекомендует использовать robocopy, так как это может привести к повреждению файлов.
В клиентских версиях, например Windows 10, официально такой роли нет, но способ установки существует. Люди, которые выполняли такую процедуру, сообщали о проблемах с программами подразумевающие синхронизацию с внешними базами данных.
Установка
В панели Server Manager открываем мастер по установке ролей и компонентов:

Пропускаем первые три шага (область 1) или выбираем другой сервер если планируем устанавливать роль не на этот сервер (область 2):

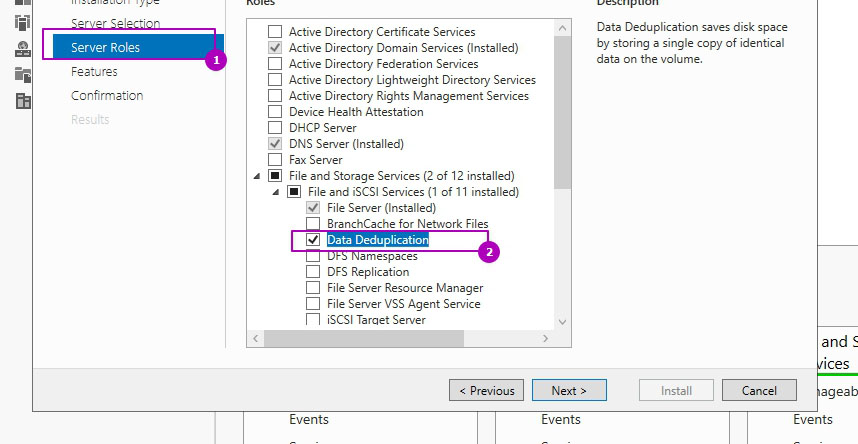
На этапе выбора ролей сервера, во вкладе "Файловые службы и службы хранилища" и "Файловые службы и службы iSCSI" выбираем "Дедупликация данных":

Раздел выбора компонентов не понадобится и его можно пропустить. На шаге подтверждения можно еще раз проверить выбранные операции и нажать кнопку установки:

Установка занимает несколько минут и без необходимости в последующей перезагрузке. Окно подтверждающее успешную установку можно закрыть:

Оценка потенциального освобождающегося места с DDPEval.exe
Вместе с установкой роли у появляется программа DDPEval.exe, позволяющая предварительно оценить пространство, которое будет освобождено в последующем.
Статистика, которую предоставляет Microsoft в зависимости от разных типов данных, примерно следующая:
- Документы пользователей - экономия 30-50%
- Установочные файлы - экономия 70-80%
- Файлы виртуализации - экономия 80-95%
- Файловые хранилища - экономия 50-60%

Для оценки места я поместил 3 одинаковых установочных архива с Exchange 2013 общим объемом 6 Гб на диск Е.
Открываем Powershell/CMD и пишем команду, которая имеет следующий синтаксис:
DDPEval.exe <раздел>
DDPEval.exe <раздел><папка>
# Пример
DDPEval.exe E:\Folder1

По каким-то причинам у меня определилась Windows 10, хотя я использую Windows Server 2019
Как можно увидеть - экономия на полностью идентичных файлах в 69 % или 4.27 Gb.
Я удалил файлы с Exchange и поместил 3 разных образа Linux (Ubuntu, Debian, Centos):


Экономия в 2%.
И последний результат с 11 разными csv/xlsx/docx файлами. Экономия 51%:

Настройка роли
Возможность управлять ролью находится на вкладе "Файловые службы":

Во вкладке по работе с разделов выберем один из них и нажмем правой кнопкой мыши. В выплывающей меню мы увидим "Настройка дедупликации данных":

По умолчанию дедупликация отключена. У нас есть выбор из трех вариантов:
- Файловый сервер общего назначения;
- Сервер инфраструктуры виртуальных рабочих столов (VDI);
- Виртуализированный резервный сервер.
Каждый из этих режимов устанавливается с рекомендуемыми настройками и дальнейшие изменения можно пропустить:

Важной настройкой является установка возраста файла (область 1), который будет проходить процесс оптимизации. Новые файлы пользователей могут активно меняться в течение нескольких дней, что в пустую увеличит нагрузку на сервер при дедупликации, а затем не открываться вовсе. Если установить значение 0, то дедупликация не будет учитывать возраст файла вовсе.
В области 2 указываются расширения файлов для исключения из процессов дедупликации. Рекомендую установить несколько расширений, которые не несут значительную роль. Затем, через недели две, оценить нагрузку на сервер и, если она будет удовлетворительной, убрать исключение. Вы можете сделать и обратную операцию, добавив в исключения расширения уже после оценки нагрузки, но этот вариант не настолько очевиден как первый. Проблема будет в том, что исключенные файлы не раздедуплицируются автоматически (только с Powershell) и они все так же будут нуждаться в поддержке и ресурсах. В области 3 исключаются папки.

В окне расписания мы можем настроить следующее:
- Фоновая оптимизация (Enable background optimization) - включена по умолчанию. Работает с низким приоритетом не мешая основным процессам. При высокой нагрузке останавливается автоматически. Срабатывает один раз в час;
- Включить оптимизацию пропускной способности (Enable throughput optimization) - расписание, когда дедупликация может выполнятся без ограничения в ресурсах. Можно настроить на выходные дни например;
- Создать второе расписание оптимизации пропускной способности (Create a second schedule for throughput optimization) - расписание аналогично предыдущему. Можно настроить на вечернее время.

На этом настройки, которые выполняются через интерфейс заканчиваются. Если снять галочку, которая включает дедупликацию, все процессы поиска и дедупликации остановятся, но файлы не вернуться в исходное положение. Для обратного преобразования файлов нужно запускать процесс Unoptimization, который выполняется в Powershell и описан ниже.
Расширенные настройки с Powershell
С помощью Powershell мы можем установить роль и настроить ее сразу на множестве компьютеров. Для установки роли локально или удаленно можно использовать следующую команду:
Install-WindowsFeature -Name "FS-Data-Deduplication" -ComputerName "Имя компьютера" -IncludeAllSubFeature -IncludeManagementTools
Следующим способом мы увидим все команды модуля дедупликации:
Get-Command -Module Deduplication

Включение и настройка дедупликации для томов
Как уже говорилось выше, при настройке в GUI у нас есть три рекомендованных режима работы с уже установленным расписанием:
- HyperV;
- Backup;
- Default (файловый сервер, устанавливается по умолчанию).
Каждый из этих режимов устанавливается для одного или множества томов следующим путем:
Enable-DedupVolume -Volume 'E:\','D:\' -UsageType 'Default'

В некоторых командах может появится ошибка, которая связана с написанием буквы раздела со слэшем. Если у вас она тоже появится попробуйте исправить 'E:\' на 'E:':
No MSFT_DedupVolume objects found with property 'Volume' equal to 'E:\'
Так мы узнаем на каких томах настроена дедупликация:
Get-DedupVolume

Так же как и в GUI мы можем ограничить обработку папок и файлов по их расширению. Для этого есть следующие аргументы:
- ExcludeFolder - ограничения на папки, например 'E:\Folder1','E:\Folder2''
- ExcludeFileType - ограничения по расширениям, например 'txt','jpg';
- MinimumFileAgeDays - минимальный возраст файла в днях, который будет оптимизироваться.
Следующий пример установит эти настройки и вернет их:
Set-DedupVolume `
-Volume 'E:' `
-ExcludeFolder 'E:\folder_exclude' `
-ExcludeFileType 'txt','rar' `
-MinimumFileAgeDays 15
Get-DedupVolume | Select *

По умолчанию дедуплкиция работает только с файлами больше чем 32Kb. В отличие от GUI это меняется в Powershell, но не в меньшую сторону. На примере ниже я установлю этот минимум для файлов в 1GB:
Set-DedupVolume `
-Volume 'E:' `
-MinimumFileSize 1GB
Get-DedupVolume | Select *

Есть еще несколько параметров, которые устанавливаются:
- ChunkRedundancyThreshold - устанавливает порог ссылок после которого будет создан еще один идентичный чанк. По умолчанию равен 100. С помощью этого параметра увеличивается избыточность. Проявляется она в более быстром и гарантированном (в случае повреждения) доступе файла. Не рекомендуется менять;
- InputOutputScale - установка значения I/O для распараллеливания процесса от 0 до 36. По умолчанию значение рассчитывается само;
- NoCompress - значению в $True или $False устанавливающая будет ли происходить сжатие;
- NoCompressionFileType - расширение файлов к которым не будет применяться сжатие;
- OptimizeInUseFiles - будут ли оптимизированы открытые файлы, например подключенные файлы VHDx;
- OptimizePartialFiles - если $True - будет работать блочная дедупликация. В ином случае будет работать файловая дедупликация;
- Verify - добавляет еще одну проверку идентичности чанков. Они будут сравниваться побайтно. Не могу сказать о ситуациях, где это могло бы пригодиться.
Для отключения используется следующая команда:
Disable-DedupVolume -Volume 'E:\'

Отключенная дедупликация не конвертирует файлы в их исходное состояние. В примере выше у нас просто не будут оптимизироваться новые файлы и выполнятся задачи. Если к команде добавить параметр -DataAccess, то мы отключим доступ к файлам прошедшим через процесс дедупликации. О том как отменить дедупликацию полностью - будет рассказано далее.
Изменение расписаний
Дедупликация делится на 4 типа задач отдельно которые можно запустить в Powershell:
- Оптимизация (Optimization) - разбиение данных на блоки, их сравнение, сжатие и помещение в хранилище System Volume Information. По умолчанию происходит раз в час;
- Сбор мусора (GarbageCollection) - удаление устаревших фрагментов (например восстановление тех данных у которых нет дубликатов). По умолчанию происходит каждую субботу;
- Проверка целостности (Scrubbing) - обнаружение повреждений в хранилище блоков и их восстановление. По умолчанию происходит каждую субботу;
- Отмена оптимизации (Unoptimization)- отмена или отключение оптимизации на томе. Выполняется по требованию.
Каждое такое задание, а так же созданные вами лично, можно увидеть в планировщике задач. Там же можно увидеть время запуска и результат выполнения:

Например можно увидеть, что задача фоновой оптимизации запускается каждый час.
Более конкретно узнать время задач мы можем через получение расписания:
Get-DedupSchedule

Задания никогда не выполняются одновременно - только в процессе очереди.
Мы можем изменить каждое из этих заданий. Например процесс GarbageCollection является очень ресурсозатратным процессом и я хочу что бы его работа начиналась в пятницу в 22:00 (по умолчанию работает в субботу в 2:45 ночи), что бы точно завершилась к понедельнику. Я так же установлю параметр StopWhenSystemBusy, который остановит процесс очистки мусора если система будет сильно нагружена другой задачей. Я сделаю это так:
Set-DedupSchedule `
-Name 'WeeklyGarbageCollection' `
-Type 'GarbageCollection' `
-Enabled $True `
-StopWhenSystemBusy $True `
-Days 'Friday' `
-Start 22:00 `

Где:
- Name - имя процесса, который мы хотим изменить;
- Type - тип процесса. В нашем случае это сборка мусора (GarbageCollection);
- Enabled - будет ли включен этот процесс;
- StopWhenSystemBusy - остановится ли процесс, если сервер будет сильно нагружен другой задачей (затем попробует запустится снова);
- Days - дни, в которые этот процесс должен запускаться;
- Start - время запуска.
Есть еще параметры, которые есть не только у этого командлета, но и у других команд дедупликации:
- DurationHours - продолжительность работы задачи в часах, после которого он будет корректно завершен. По умолчанию равен 0, что означает работу до полного завершения без ограничения во времени.
- Full - параметр со значениями $True и $False. Зависит от того что указано в Type. Если мы выполняем сборку мусора, то этот параметр будет удалять все устаревшие данные сразу, а не до достижения определенного порога. При выполнении очистки (Scrubbing), если указан параметр Full, происходит проверка всех данных, а не только критически важных. В обоих случаях этот параметр стоит использовать раз в месяц.
- ReadOnly - при работе очистки не исправляет ошибки, а только уведомляет
Кроме этого, почти во всех командах при работе с дедупликацией есть настройка ресурсов, которые мы планируем выделять:
- Cores - число с количеством ядер (в процентном соотношении), которые будут участвовать в процессе;
- Memory - количество памяти от общего значения (в процентном соотношении);
- StopWhenSystemBusy - останавливает задачу, если сервер, в данный момент, сильно нагружен (возобновляет ее позже);
- Priority - указывает тип нагрузки на процессор (ввод, вывод) со значениями: Low, Normal, High;
- InputOutputThrottle - ограничения работы ввода вывода при троттлинге в значениях от 0 до 100,;
- InputOutputThrottleLevel - ограничения работы ввода вывода при троттлинге со следующими значениями: None, Low, Medium, High. InputOutputThrottle имеет более высокий приоритет и при установке двух аргументов - InputOutputThrottleLevel может не работать.
- ThrottleLimit - указывает предел троттлинга. Если указан 0, то расчет будет выполнен автоматически.
На примере параметров выше я создам новую задачу по оптимизации. Она будет проходить в будни, после 21:00, с нагрузкой в 70% от максимальной на протяжении 8 часов:
New-DedupSchedule `
-Name 'Оптимизация по будням' `
-Cores 80 `
-Days Monday,Tuesday,Wednesday,Thursday,Friday `
-DurationHours 8 `
-InputOutputThrottleLevel Medium `
-Priority Normal `
-Memory 80 `
-Start 21:00 `
-Type 'Optimization' `
-StopWhenSystemBusy `

Обращу внимание, что мы можем не писать все эти настройки, а просто копировать их используя обычные методы Powershell. Так я создам копию задачи очистки (Scrubbing), которая будет дополнена ключом Full и отключена по умолчанию:
Get-DedupSchedule -Name '*Scrub*' | New-DedupSchedule `
-Name 'Полная проверка целостности раз в месяц' `
-Full `
-Disable `

Так же можно и удалять задачи:
Get-DedupSchedule -Name '*Полная*' | Remove-DedupSchedule
# или
Remove-DedupSchedule -Name '*Полная*'

Если вы убрали дедупликацию на томе и планируете обратить файлы в исходное состояние вы можете выполнить следующую команду установив свои настройки:
New-DedupSchedule -Type Unoptimization
Учитывайте, что вам потребуется больше свободного пространства для файлов (иначе дедупликация остановится с ошибкой) и процесс займет много ресурсов и времени. Копирование данных на другой том так же возможен и в этом случае файл тоже вернется в исходное состояние.
Запуск отдельных задач
Предыдущий пример, где мы устанавливали параметр Full, для проверки целостности всей базы, был не очень удачный. Дело в том, что мы можем устанавливать расписание только на неделю, а такая проверка рекомендуется раз в месяц. Для исправления этой ситуации мы можем использовать разовые задачи. Так я создам и запущу похожую задачу:
Start-DedupJob `
-Full `
-Volume 'E:\' `
-Type 'Scrubbing'

Вернуть состояние задачи можно так:
Get-DedupJob

Если у вас есть настроенное расписание, то вы тоже его можете скопировать и запустить т.е. использовать как шаблон. Такая возможность явно не планировалась разработчиками и поэтому могут быть ошибки на этапе запуска. Например у меня была такие ошибки:
- Exception calling "EndProcessing" with "0" argument(s)
- Start-DedupJob : MSFT_DedupVolume.Volume='
Одна из них была связана с отсутствием буквы раздела, так как я его не указал. Я дополнил параметры и все сработало корректно. Так же как и на примерах выше мы можем исправлять шаблон из планировщика как хотим. Ошибки могут быть разными, но они достаточно ясные и легко исправляются:
Get-DedupSchedule -Name '*полная проверка*' | Start-DedupJob -InputOutputThrottleLevel Low -Volume 'E:'

Так же как и при создании запланированной задачи мы можем установить следующие параметры (более детально они описаны выше):
- Cores
- Full
- InputOutputThrottle
- InputOutputThrottleLevel
- Memory
- Priority
- ReadOnly
- StopWhenSystemBusy
- ThrottleLimit
- Type
А эти параметры есть только у Start-DedupSchedule:
- Preempt - форсированный запуск задачи, отменяющий иные;
- Timestamp - работает только с задачами типа 'Unoptimization' и принимает значения типа данных DateTime. Отменяет оптимизацию файлов оптимизированных с указанной даты;
- Volume - можно указать один или несколько томов. Можно указывать буквы формата 'E:', ID и GUID;
- Wait - в фоне будет отображаться процесс задачи и ее результат. Пример ниже.

Пример отмены задач:
Get-DedupJob -Type Scrubbing | Stop-DedupJob
# или
Stop-DedupJob -Volume 'E:','C:'
Отмену дедупликации вы так же можете запустить задачей:
Start-DedupJob -Type Unoptimization
Статус дедупликации
Следующая команда вернет текущий статус дедупликации:
# Сокращенный вариант
Get-DedupStatus
# Полный отчет
Get-DedupStatus | select *

Предыдущая команда возвращает закэшированные данные, но если вы хотите получить наиболее актуальную информацию вы можете выполнить следующую команду:
# Для всех томов
Update-DedupStatus
# Для одного тома
Update-DedupStatus -Volume 'E:'
# Возвращение полной актуальной информации по тому
Update-DedupStatus -Volume 'E:' | SELECT *

Следующая команда вернет время последнего выполнения каждого из процессов дедупликации:
Get-DedupStatus -Volume 'E:' | select -Property "*time*" | fl

Эта команда вернет информацию по работе с файлами:
Get-DedupStatus -Volume 'E:' | select -Property "*file*",'s*rate*' | fl

Где:
- InPolicyFilesCount - количество файлов, которые подходят для оптимизации;
- InPolicyFilesSize - общий размер файлов, которые подходят для оптимизации;
- OptimizedFilesCount - количество файлов, которые были оптимизированы;
- OptimizedFilesSavingRate - процент оптимизированных файлов относительно всех файлов которые подходят под установленные параметры;
- OptimizedFilesSize - общий размер оптимизированных файлов.
Более точно эти данные отображаются после процесса сборки мусора и оптимизации.
Следующая команда вернет данные из базы дедупликации по определенному тому:
Get-DedupMetadata -Volume 'E:'

Если такой запрос завершится ошибкой, то скорее всего, в данный момент, происходит один из процессов дедупликации, который меняет эти метаданные.
По выводу мы можем увидеть:
- DataChunkCount - количество чанков, размером 32-128 Кб на одном томе;
- DataContainerCount - количество контейнеров;
- DataChunkAverageSize - средний размер одного чанка (размер контейнера поделенный на количество чанков);
- TotalChunkStoreSize - размер хранилища;
- CorruptionLogEntryCount - количество ошибок на томе.
Свойства типа "Stream*" скорее всего показывают данные по открытым файлам или проходящие через Volume Shadow Copy.
Если будет необходимость в освобождения места (переносом или удалением) подсчет потенциально освобождающегося пространства будет сложной задачей. Связано это с тем, что не ясно количество дедуплицированных файлов (они могут быть в трех, четырех копиях, в разных местах и т.д.). В этом случае можно использовать команду Measure-DedupFileMetadata:
Measure-DedupFileMetadata -Path 'E:\New folder\'

Где:
- FilesCount - количество файлов на всем томе;
- OptimizedFilesCount - количество оптимизированных файлов на всем томе;
- Size - суммарный размер всех файлов;
- DedupSize - итоговый размер дедуплицированных файлов в этой папке;
Восстановление дедуплицированных файлов
Команда Expand-DedupFile восстанавливает файл, который был оптимизирован в его исходное место. Такая операция может понадобится, когда стороннее приложение (например программы бэкапа) не могут корректно работать с файлом. Важным моментом восстановления таких файлов является достаточное количество места на диске. Следующим образом я восстановлю два файла в их исходное местоположение:
Expand-DedupFile -Path 'E:\New folder\Otchet2020.doc','E:\New folder\3285.wav'
Никакого вывода команда не выдает, но если файл не был дедуплицирован, то вы получите ошибку:
Expand-DedupFile : MSFT_DedupVolume.Path='E:\file1' - HRESULT 0x80070057, The parameter is incorrect.
...

